Volume-basierte vs. Ephemeral-basierte Speicherung für Kubernetes-Cluster auf EO-Lab OpenStack Magnum
Container in Kubernetes speichern Dateien auf der Festplatte, und wenn der Container abstürzt, gehen die Daten verloren. Ein neuer Container kann den alten ersetzen, aber die Daten bleiben nicht erhalten. Ein weiteres Problem tritt auf, wenn Container, die in einem Pod laufen, Dateien gemeinsam nutzen müssen.
Aus diesem Grund gibt es in Kubernetes eine weitere Art von Dateispeicher, die sogenannten Volumes. Sie können entweder persistent oder ephemer sein, gemessen an der Lebensdauer eines Pods:
Ephemere Volumes werden gelöscht, wenn der Pod gelöscht wird, während
Persistente Volumes bestehen bleiben, auch wenn der Pod, dem sie zugeordnet sind, nicht mehr existiert.
Das Konzept der Volumes wurde zuerst von Docker populär gemacht, wo es ein Verzeichnis auf der Festplatte oder innerhalb eines Containers war. Beim OpenStack-Hosting ist der Docker-Speicher standardmäßig so konfiguriert, dass er die ephemere Festplatte der Instanz verwendet. Dies kann durch die Angabe der Docker-Volume-Größe während der Cluster-Erstellung geändert werden, symbolisch wie folgt (siehe weiter unten für den vollständigen Befehl zur Erstellung eines neuen Clusters mit –docker-volume-size):
openstack coe cluster create --docker-volume-size 50
Dies bedeutet, dass ein persistentes Volume von 50 GB erstellt und an den Pod angehängt wird. Die Verwendung von –docker-volume-size ist eine Möglichkeit, sowohl den Speicherplatz zu reservieren als auch ihn als persistent zu deklarieren.
Was wir behandeln werden
Wie wird ein Cluster erstellt, wenn –docker-volume-size verwendet wird?
Wie erstellt man ein Pod-Manifest mit emptyDir als Volume?
Erstellen eines Pods mit diesem Manifest
Ausführen von bash-Befehlen im Container
Wie man eine Datei im persistenten Speicher speichert
Wie demonstriert man, dass das angeschlossene Volume persistent ist?
Voraussetzungen
Nr. 1 Konto
Sie benötigen ein EO-Lab Konto mit Horizon interface https://cloud.fra1-1.cloudferro.com/auth/login/?next=/.
Nr. 2 Erstellen von Clustern mit CLI
Der Artile So verwenden Sie die Befehlszeilenschnittstelle für Kubernetes-Cluster auf EO-Lab OpenStack Magnum führt Sie in die Erstellung von Clustern über eine Befehlszeilenschnittstelle ein.
Nr. 3 Openstack-Client mit der Cloud verbinden
Bereiten Sie Openstack- und Magnum-Clients vor, indem Sie Schritt 2 OpenStack- und Magnum-Clients mit Horizon Cloud verbinden aus dem Artikel ausführen Installation von OpenStack- und Magnum-Clients für die Befehlszeilenschnittstelle von EO-Lab Horizon
Nr. 4 Verfügbare Quotas prüfen
Bevor Sie weitere Cluster erstellen, überprüfen Sie den Status der Ressourcen mit den Horizon-Befehlen Computer => Übersicht.
5 Private und public keys
Ein SSH-Schlüsselpaar, das in OpenStack Dashboard erstellt wurde. Um es zu erstellen, folgen Sie diesem Artikel Wie erstellt man ein Schlüsselpaar im OpenStack Dashboard?. Sie erstellen ein Schlüsselpaar namens „sshkey“, das Sie auch für dieses Tutorial verwenden können.
6 Arten von Volumes
Die Arten von Volumes werden in der offiziellen Kubernetes-Dokumentation beschrieben <https://kubernetes.io/docs/concepts/storage/volumes/>`_.
Schritt 1 - Cluster mit –docker-volume-size erstellen
Mit dem folgenden Befehl erstellen Sie einen neuen Cluster namens dockerspace, der den Parameter –docker-volume-size verwenden wird:
openstack coe cluster create dockerspace
--cluster-template k8s-stable-1.23.5
--keypair sshkey
--master-count 1
--node-count 2
--docker-volume-size 50
--master-flavor eo1.large
--flavor eo2.large
Nach ein paar Minuten wird der neue Cluster dockerspace erstellt.
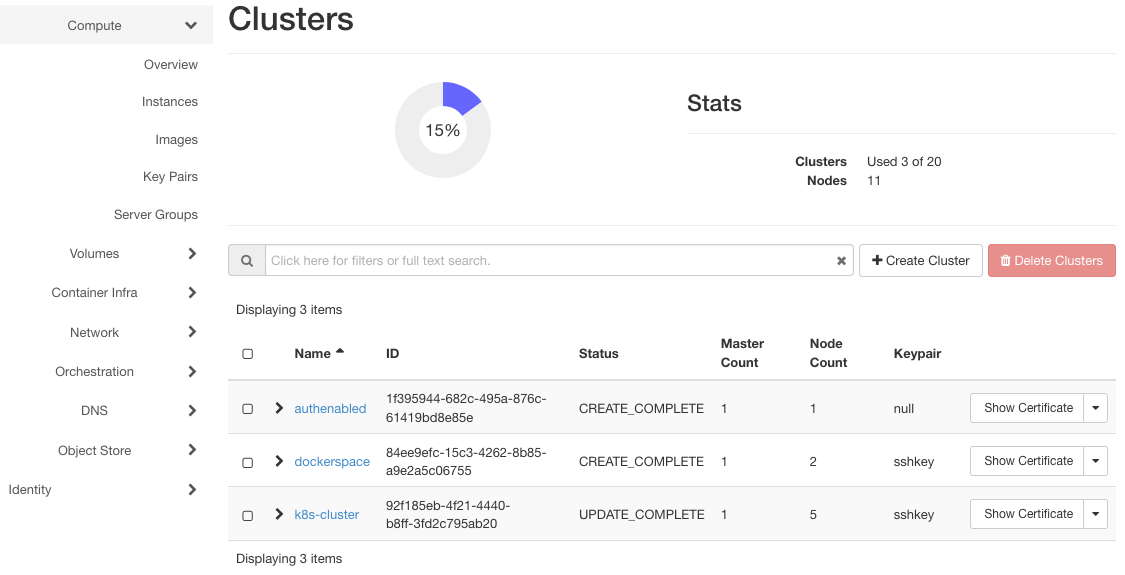
Klicken Sie auf Container Infra => Clusters, um die drei Cluster im System anzuzeigen: authenabled, k8s-cluster und dockerspace.
Hier sind ihre Instanzen (nach Anklicken von Compute => Instances):
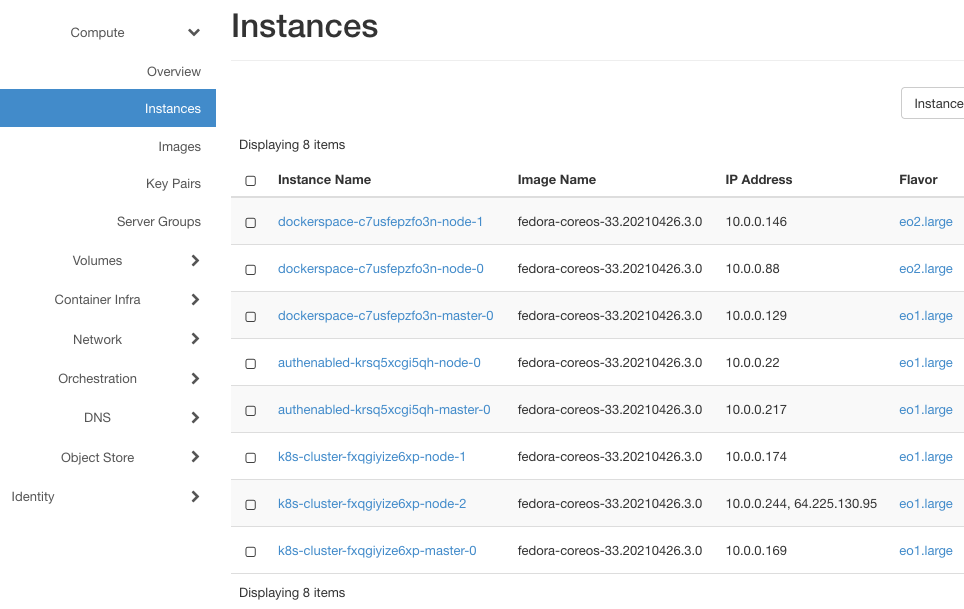
Sie haben jeweils mindestens zwei Instanzen, eine für den Master und eine für den Worker Node. dockerspace hat drei Instanzen, da es zwei Arbeitsknoten hat, die mit dem Flavor eo2.large erstellt wurden.
So weit so gut, nichts Ungewöhnliches. Klicken Sie auf Volumes => Volumes, um die Liste der Volumes anzuzeigen:
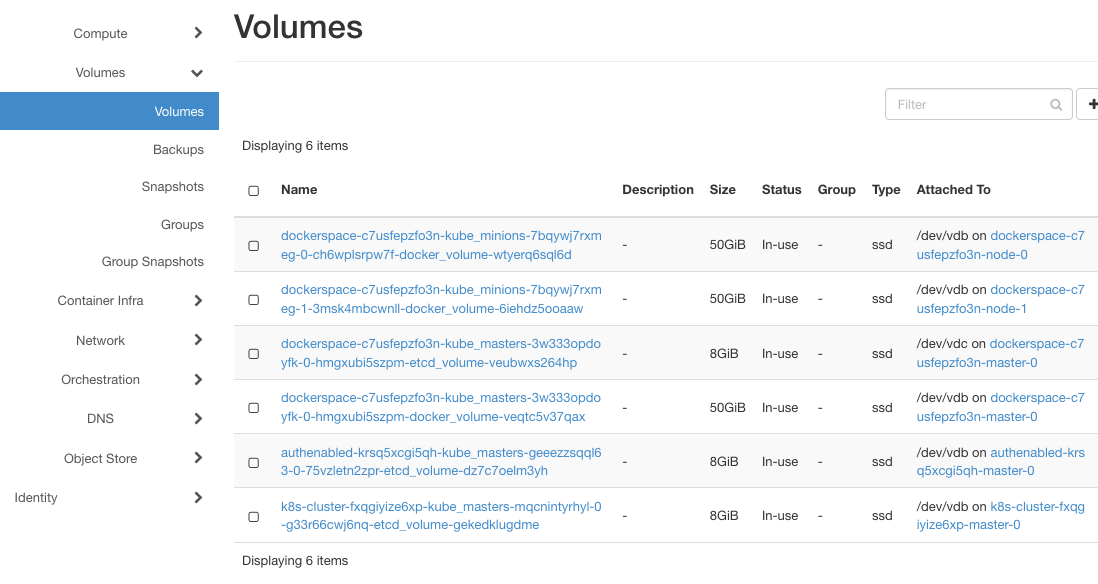
Wenn –docker-volume-size nicht aktiviert ist, würden hier nur Instanzen mit etcd-volume im Namen erscheinen, wie es bei den Clustern authenabled und k8s-cluster der Fall ist. Wenn es aktiviert ist, werden zusätzliche Volumes angezeigt, eines für jeden Knoten. dockerspace hat also eine Instanz für den Master und zwei Instanzen für die Arbeitsknoten.
Beachten Sie die Spalte Attached. Alle Knoten für dockerspace verwenden /dev/vdb für die Speicherung, eine Tatsache, die später wichtig sein wird.
Wie bei der Erstellung angegeben, haben die docker-volumes eine Größe von jeweils 50 GB.
In diesem Schritt haben Sie einen neuen Cluster mit aktiviertem Docker-Storage erstellt und dann überprüft, dass der Hauptunterschied in der Erstellung von Volumes für den Cluster liegt.
Schritt 2 - Pod-Manifest erstellen
Um einen Pod zu erstellen, müssen Sie eine Datei im yaml-Format verwenden, die die Parameter des Pods definiert. Verwenden Sie den Befehl
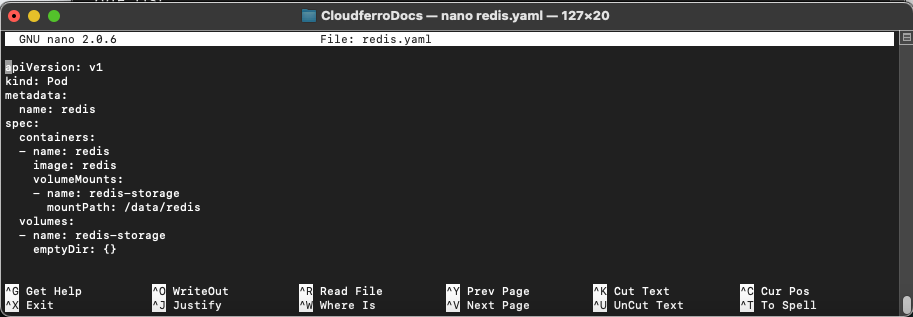
nano redis.yaml
um eine Datei mit dem Namen redis.yaml zu erstellen und kopieren Sie die folgenden Zeilen hinein:
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {}
Im Terminal sieht es dann so aus:
Sie erstellen einen Pod mit dem Namen redis, der einen Container mit dem Namen redis belegt. Der Inhalt dieses Containers wird ein Image namens redis sein.
Redis ist eine bekannte Datenbank, deren Image im Voraus vorbereitet wird und direkt aus einem Repository gezogen werden kann. Wenn Sie Ihre eigene Anwendung implementieren würden, wäre es am besten, sie über Docker freizugeben und aus dem Repository zu ziehen.
Das neue Volume wird redis-storage genannt und sein Verzeichnis lautet /data/redis. Der Name des Volumes wird wieder redis-storage lauten und es wird vom Typ emptyDir sein.
Ein emptyDir-Volume ist anfangs leer und wird erstmals erstellt, wenn ein Pod einem Knoten zugewiesen wird. Es existiert so lange, wie der Pod dort läuft. Wird der Pod entfernt, werden die zugehörigen Daten in emptyDir dauerhaft gelöscht. Die Daten in einem emptyDir-Volume sind jedoch über Container-Abstürze hinweg sicher.
Neben emptyDir hätten hier etwa ein Dutzend anderer Volume-Typen verwendet werden können: awsElasticBlockStore, azureDisk, cinder und so weiter.
In diesem Schritt haben Sie das Pod-Manifest vorbereitet, mit dem Sie im nächsten Schritt den Pod erstellen werden.
Schritt 3 - Erstellen eines Pods auf Knoten 0 von dockerspace.
In diesem Schritt erstellen Sie einen neuen Pod auf dem Knoten 0 des Clusters dockerspace.
Sehen Sie zunächst nach, welche Pods im Cluster verfügbar sind:
kubectl get pods
Das kann zu Fehlermeldungen wie dieser führen:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
Dies ist der Fall, wenn Sie die kubectl-Parameter nicht wie in Voraussetzungen Nr. 3 angegeben eingerichtet haben. Jetzt richten Sie ihn für den Zugriff auf dockerstate ein:
mkdir dockerspacedir
openstack coe cluster config
--dir dockerspacedir
--force
--output-certs
dockerspace
Erstellen Sie zunächst ein neues Verzeichnis, dockerspacedir, in dem sich die Konfigurationsdatei für den Zugriff auf den Cluster befinden wird, und führen Sie dann den Befehl cluster config aus. Die Ausgabe wird eine Zeile wie diese sein:
export KUBECONFIG=/Users/duskosavic/CloudferroDocs/dockerspacedir/config
Kopieren Sie ihn und geben Sie ihn den Befehl im Terminal ein. Dadurch erhält die App kubectl Zugriff auf den Cluster. Erstellen Sie den Pod mit diesem Befehl:
kubectl apply -f redis.yaml
Es liest die Parameter in der Datei redis.yaml und sendet sie an den Cluster.
Hier ist der Befehl für den Zugriff auf alle Pods, falls vorhanden:
kubectl get pods
NAME READY STATUS RESTARTS AGE
redis 0/1 ContainerCreating 0 7s
Wiederholen Sie den Befehl nach ein paar Sekunden und sehen Sie den Unterschied:
kubectl get pods
NAME READY STATUS RESTARTS AGE
redis 1/1 Running 0 81s
In diesem Schritt haben Sie einen neuen Pod auf dem Cluster dockerspace erstellt, der läuft.
Im nächsten Schritt geben Sie innerhalb des Containers Befehle ein, wie Sie es in jeder anderen Linux-Umgebung tun würden.
Schritt 4 - Ausführen von bash-Befehlen im Container
In diesem Schritt starten Sie die bash-Shell im Container, was unter Linux gleichbedeutend mit dem Start des Betriebssystems ist:
kubectl exec -it redis -- /bin/bash
Die folgende Auflistung wird ausgegeben:
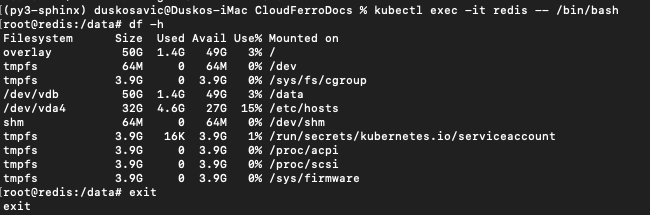
root@redis:/data# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 50G 1.4G 49G 3% /
tmpfs 64M 0 64M 0% /dev
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/vdb 50G 1.4G 49G 3% /data
/dev/vda4 32G 4.6G 27G 15% /etc/hosts
shm 64M 0 64M 0% /dev/shm
tmpfs 3.9G 16K 3.9G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 3.9G 0 3.9G 0% /proc/acpi
tmpfs 3.9G 0 3.9G 0% /proc/scsi
tmpfs 3.9G 0 3.9G 0% /sys/firmware
So würde es im Terminal aussehen:
Beachten Sie, dass sich die Eingabeaufforderung geändert hat:
root@redis:/data#
Das bedeutet, dass Sie nun Befehle innerhalb des Containers selbst erteilen. Der Pod arbeitet als Fedora 33 und Sie können df verwenden, um die Volumes und ihre Größen zu sehen. Der Befehl
df -h
listet die Größen von Dateien und Verzeichnissen in verständlicher Form auf (die übliche Bedeutung des Parameters -h wäre Hilfe, während er hier kurz ist für Human steht).
Mit diesem Schritt haben Sie das Container-Betriebssystem aktiviert.
Schritt 5 - Speichern einer Datei im persistenten Speicher
In diesem Schritt werden Sie die Langlebigkeit von Dateien auf einem dauerhaften Speicher testen. Sie werden zuerst
eine Datei in das Verzeichnis /data/redis speichern, dann
beenden Sie den Redis-Prozess, der seinerseits
den Container beenden; schließlich werden Sie
den Pod wieder öffnen,
wo Sie die Datei unversehrt vorfinden.
Beachten Sie, dass dev/vdb in der obigen Auflistung 50 GB groß ist und verbinden Sie es mit der Spalte Angeschlossen an in der Auflistung Volumes => Volumes:

Sie ist ihrerseits an eine Instanz gebunden:

Diese Instanz wird in den Container injiziert und fungiert - als unabhängige Instanz - als persistenter Speicher für den Pod.
Erstellen Sie eine Datei auf dem Container redis:
cd /data/redis/
echo Hello > test-file
Software installieren, um die PID-Nummer des Redis-Prozesses im Container zu sehen
apt-get update
apt-get install procps
ps aux
Dies sind die laufenden Prozesse:

Nehmen Sie die PID Nummer des Redis Prozesses (hier ist es 1), und eliminieren Sie sie mit dem Befehl
kill 1
Dadurch wird zuerst der Container beendet und seine Befehlszeile verlassen.
In diesem Schritt haben Sie eine Datei erstellt und den Container, der die Datei enthält, beendet. Das ist die Voraussetzung, um zu testen, ob die Dateien einen Containerabsturz überleben.
Schritt 6 - Prüfen Sie die im vorherigen Schritt gespeicherte Datei
In diesem Schritt werden Sie herausfinden, ob die Datei test-file noch vorhanden ist.
Öffnen Sie den Pod erneut, aktivieren Sie seine bash-Shell und sehen Sie nach, ob die Datei überlebt hat:
kubectl exec -it redis -- /bin/bash
cd redis
ls
test-file
Die Datei test-file ist also vorhanden. Der dauerhafte Speicher für den Pod enthält sie im Pfad /data/redis:

In diesem Schritt haben Sie den Pod erneut betreten und festgestellt, dass die Datei unversehrt überlebt hat. Das war zu erwarten, da Volumes vom Typ emptyDir Containerabstürze überleben, solange der Pod existiert.
Was ist als nächstes zu tun?
emptyDir überlebt Container-Abstürze, verschwindet aber, wenn der Pod verschwindet. Andere Volume-Typen überstehen den Verlust von Pods möglicherweise besser. Zum Beispiel:
Bei awsElasticBlockStore wird das Volume ausgehängt, wenn der Pod verschwindet; da es ausgehängt und nicht zerstört wird, bleiben die Daten, die es enthält, erhalten. Dieser Volume-Typ kann mit existierenden Daten vorbesetzt werden, Daten können zwischen Pods geteilt werden.
cephfs kann ebenfalls vorgespeicherte Daten halten und diese unter den Pods teilen, kann aber zusätzlich auch von mehreren Pods gleichzeitig gemountet werden.
Es können auch andere Beschränkungen gelten. Einige dieser Datenträgertypen erfordern, dass ihre eigenen Server zuerst aktiviert werden, oder dass alle Knoten, auf denen Pods laufen, vom gleichen Typ sein müssen und so weiter. In Voraussetzung Nr. 6 werden alle Arten von Volumes für Kubernetes-Cluster aufgelistet, also studieren Sie sie und wenden Sie sie auf Ihre eigenen Kubernetes-Anwendungen an.