Nutzen Sie Argo Workflows auf EO-Lab FRA1-1 Magnum Kubernetes
Argo Workflows ermöglicht die Ausführung komplexer Job-Workflows auf Kubernetes. Es kann
eine benutzerdefinierte Logik für die Verwaltung von Abhängigkeiten zwischen Aufträgen bereitstellen,
Situationen bewältigen, in denen bestimmte Schritte des Workflows fehlschlagen,
parallele Ausführung von Aufträgen, um Zahlen für die Datenverarbeitung oder maschinelle Lernaufgaben zu verarbeiten,
CI/CD-Pipelines ausführen,
Workflows mit gerichteten azyklischen Graphen (Directed Acyclic Graphs, DAG) erstellen usw.
Argo wendet einen Microservice-orientierten, Container-nativen Ansatz an, bei dem jeder Schritt eines Workflows als Container ausgeführt wird.
Was wir behandeln werden
Authentifizierung beim Cluster
Vorläufige Konfiguration auf PodSecurityPolicy anwenden
Argo-Workflows auf dem Cluster installieren
Argo-Workflows aus der Wolke ausführen
Argo-Workflows lokal ausführen
Beispiel-Workflow mit zwei Aufgaben ausführen
Voraussetzungen
- No. 1 Konto
Sie benötigen ein Hosting-Konto mit Zugriff auf die Horizon-Schnittstelle: https://cloud.fra1-1.cloudferro.com/auth/login/?next=/.
- Nr. 2 kubectl zeigt auf den Kubernetes-Cluster
Wenn Sie einen neuen Cluster erstellen, nennen Sie ihn für die Zwecke dieses Artikels argo-cluster. Siehe Zugriff auf Kubernetes-Cluster nach der Bereitstellung mit Kubectl auf EO-Lab OpenStack Magnum
Authentifizierung beim Cluster
Lassen Sie uns bei argo-cluster authentifizieren. Führen Sie von Ihrem lokalen Rechner aus den folgenden Befehl aus, um eine Konfigurationsdatei im aktuellen Arbeitsverzeichnis zu erstellen:
openstack coe cluster config argo-cluster
Dies gibt den Befehl zum Setzen der Umgebungsvariablen KUBECONFIG aus, die auf den Speicherort Ihres Clusters verweist, z. B.
export KUBECONFIG=/home/eouser/config
Führen Sie diesen Befehl aus.
Vorläufige Konfiguration anwenden
OpenStack Magnum wendet standardmäßig bestimmte Sicherheitsbeschränkungen für Pods an, die auf dem Cluster laufen, die mit der Praxis der „geringsten Privilegien“ übereinstimmen. Argo Workflows benötigen einige zusätzliche Privilegien, um korrekt zu laufen.
Erstellen Sie zunächst einen dedizierten Namespace für Argo-Workflow-Artefakte:
kubectl create namespace argo
Der nächste Schritt ist die Erstellung einer RoleBinding, die eine magnum:podsecuritypolicy:privileged ClusterRole hinzufügt. Erstellen Sie eine Datei argo-rolebinding.yaml mit dem folgenden Inhalt:
argo-rolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: argo-rolebinding
namespace: argo
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:serviceaccounts
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: magnum:podsecuritypolicy:privileged
und wenden Sie diese an:
kubectl apply -f argo-rolebinding.yaml
Argo-Workflows installieren
Um Argo auf dem Cluster zu installieren, führen Sie den folgenden Befehl aus:
kubectl apply -n argo -f https://github.com/argoproj/argo-workflows/releases/download/v3.4.4/install.yaml
Es gibt auch ein Argo CLI, mit dem Sie Aufträge über die Kommandozeile ausführen können. Die Installation liegt außerhalb des Rahmens dieses Artikels.
Argo-Workflows aus der Cloud ausführen
Normalerweise müssen Sie sich beim Server über ein UI-Login authentifizieren. Hier werden wir den Authentifizierungsmodus ändern, indem wir den folgenden Patch auf die Bereitstellung anwenden. (Für die Produktion müssen Sie möglicherweise einen geeigneten Authentifizierungsmechanismus einbauen). Geben Sie den folgenden Befehl ein:
kubectl patch deployment \
argo-server \
--namespace argo \
--type='json' \
-p='[{"op": "replace", "path": "/spec/template/spec/containers/0/args", "value": [
"server",
"--auth-mode=server"
]}]'
Der Argo-Dienst wird standardmäßig als Kubernetes-Dienst vom Typ ClusterIp bereitgestellt, was durch Eingabe des folgenden Befehls überprüft werden kann:
kubectl get services -n argo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
argo-server ClusterIP 10.254.132.118 <none> 2746:31294/TCP 1d
Um diesen Dienst über das Internet zugänglich zu machen, wandeln Sie den Typ ClusterIP in LoadBalancer um, indem Sie den Dienst mit dem folgenden Befehl patchen:
kubectl -n argo patch service argo-server -p '{"spec": {"type": "LoadBalancer"}}'
Nach ein paar Minuten wird ein Cloud LoadBalancer generiert und die externe IP wird eingetragen:
kubectl get services -n argo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
argo-server LoadBalancer 10.254.132.118 64.225.134.153 2746:31294/TCP 1d
Die IP-Adresse lautet in unserem Fall 64.225.134.153.
Argo wird standardmäßig über HTTPS mit einem selbstsignierten Zertifikat auf Port 2746 bedient. Wenn Sie also https://<ihre-service-externe-ip>:2746 eingeben, sollten Sie auf den Dienst zugreifen können:
Beispiel-Workflow ausführen
Um einen Beispiel-Workflow auszuführen, schließen Sie zunächst die ersten Pop-ups in der Benutzeroberfläche. Gehen Sie dann zum Symbol „Workflows“ oben links und klicken Sie darauf, dann müssen Sie im folgenden Pop-up auf „Weiter“ klicken.
Im nächsten Schritt klicken Sie auf die Schaltfläche „Neuen Workflow einreichen“ im oberen linken Teil des Bildschirms, woraufhin ein Bildschirm ähnlich dem unten abgebildeten erscheint:
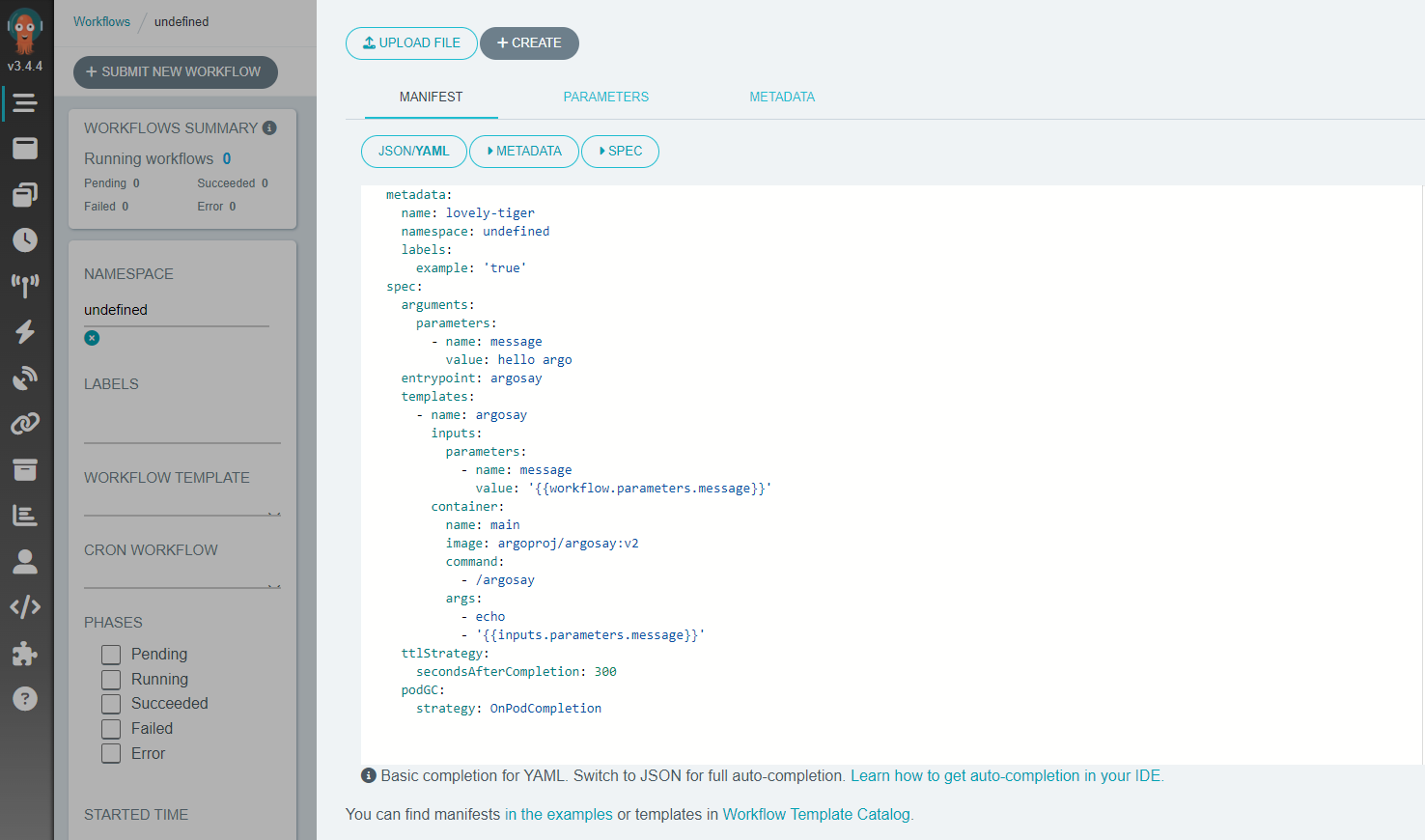
Obwohl Sie den von Argo bereitgestellten Arbeitsablauf als Ausgangspunkt verwenden können, stellen wir hier ein alternatives Minimalbeispiel zur Verfügung. Um es auszuführen, erstellen Sie eine Datei, die wir argo-article.yaml nennen und an die Stelle des YAML-Manifests des Beispiels kopieren können:
argo-article.yaml
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: workflow-
namespace: argo
spec:
entrypoint: my-workflow
serviceAccountName: argo
templates:
- name: my-workflow
dag:
tasks:
- name: downloader
template: downloader-tmpl
- name: processor
template: processor-tmpl
dependencies: [downloader]
- name: downloader-tmpl
script:
image: python:alpine3.6
command: [python]
source: |
print("Files downloaded")
- name: processor-tmpl
script:
image: python:alpine3.6
command: [python]
source: |
print("Files processed")
Dieses Beispiel simuliert einen Arbeitsablauf mit 2 Aufgaben/Arbeitsplätzen. Zuerst läuft die Downloader-Aufgabe, danach übernimmt die Prozessor-Aufgabe ihren Teil. Einige Highlights zu dieser Workflow-Definition:
Beide Aufgaben werden als Container ausgeführt. Für jede Aufgabe wird also zunächst der Container python:alpine3.6 aus der DockerHub-Registrierung gezogen. Dann führt dieser Container eine einfache Aufgabe aus, nämlich das Drucken eines Textes. In einem Produktions-Workflow würde der Code mit Ihrer Logik statt eines Skripts als benutzerdefiniertes Docker-Image aus Ihrer Container-Registry gezogen werden.
Die Reihenfolge der Ausführung des Skripts wird hier mit DAG (Directed Acyclic Graph) definiert. Dies ermöglicht es, die Abhängigkeiten der Aufgaben im Abschnitt Abhängigkeiten anzugeben. In unserem Fall liegt die Abhängigkeit beim Processor, so dass dieser erst nach Beendigung des Downloaders gestartet wird. Würden wir die Abhängigkeiten zum Processor weglassen, würde dieser parallel zum Downloader laufen.
Jede Aufgabe in dieser Sequenz wird als Kubernetes-Pod ausgeführt. Wenn eine Aufgabe erledigt ist, wird der Pod abgeschlossen, wodurch die Ressourcen im Cluster freigegeben werden.
Sie können dieses Beispiel ausführen, indem Sie auf die Schaltfläche „+Create“ klicken. Sobald der Workflow abgeschlossen ist, sollten Sie ein Ergebnis wie unten sehen:

Wenn Sie auf die einzelnen Schritte klicken, werden auf der rechten Seite des Bildschirms außerdem weitere Informationen angezeigt. Wenn man z. B. auf den Schritt „Prozessor“ klickt, werden unten rechts auf dem Bildschirm seine Protokolle angezeigt.
Die Ergebnisse zeigen, dass tatsächlich die Meldung „Files processed“ im Container gedruckt wurde:
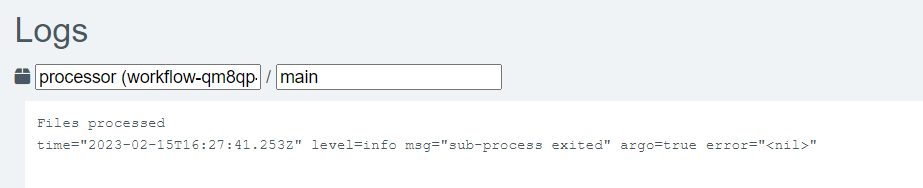
Was als nächstes zu tun ist
Ziehen Sie für die Produktion alternative Authentifizierungsmechanismen in Betracht und ersetzen Sie selbstsignierte HTTPS-Zertifikate durch solche, die von einer Zertifizierungsstelle generiert wurden.