Beispiel für einen Deep-Learning-Workflow mit TensorFlow und Docker auf einer virtuellen Maschine mit vGPU auf EO-Lab
Hier werden die Deep Learning-Tools TensorFlow und Keras zur Durchführung einer benutzerdefinierten Bildklassifizierung auf vGPU in der Cloud FRA1-1 verwendet.
Die Verwendung von (v)GPU beschleunigt die mit Deep Learning verbundenen Berechnungen. In diesem Beispiel wird die Verarbeitungszeit von ein paar Stunden auf ein paar Minuten verkürzt.
Die Aufgabe, auf die Sie TensorFlow anwenden werden, besteht darin, zu erkennen, welche Bildsätze zurechtgeschnitten sind und welche nicht. In den beiden unten gezeigten Bildsätzen sind die Bilder auf der linken Seite nicht beschnitten, während die Bilder auf der rechten Seite beschnitten sind. Das Modell, das Sie in diesem Artikel entwickeln werden, wird in der Lage sein, (mehr oder weniger) die gleichen Schlussfolgerungen zu ziehen wie ein Mensch für den gleichen Satz von Bildern.

Warnung
Die Verarbeitung von Satellitenbildern ist eine eigene Disziplin, bei der verschiedene Techniken zum Einsatz kommen. Dieser Artikel konzentriert sich auf die absoluten Grundlagen, um das Konzept und einen möglichen Arbeitsablauf beim Einsatz von Deep Learning auf einer vGPU-Maschine zu demonstrieren.
Außerdem ist das hier entwickelte Modell nur ein Beispiel. Die Verwendung in der Produktion würde umfangreiche weitere Tests erfordern. Das Modell ist nicht deterministisch und wird bei jedem Training andere Ergebnisse liefern.
Wenn Sie diesen Deep-Learning-Workflow ohne Docker durchführen möchten, lesen Sie stattdessen die folgenden Artikel: TensorFlow auf ei er FRA1-1 vGPU-fähiger VM auf EO-Lab installieren und Beispiel für einen Deep Learning-Workflow mit einer FRA1-1 vGPU VM EO-Lab.
Was wir tun werden
Gründliche Erläuterung des in diesem Prozess verwendeten Python-Codes.
Docker als Umgebung für die Modellentwicklung verwenden.
Erstellen eines benutzerdefiniertes Container-Image mit dem Namen deeplearning auf der Grundlage des öffentlichen Images tensorflow/tensorflow:2.11.0-gpu.
Herunterladen von Daten zum Testen und Trainieren.
Installieren des Python-Skript deeplearning.py im Docker-Container.
Installieren von erforderlichen Abhängigkeiten (pandas und numpy).
Anwenden des Modells mit den Daten, die für diesen Artikel verwendet werden.
Analysieren der Ergebnisse.
Testen des Modells auf den Flavors vm.a6000.1 und vm.a6000.8 , Vergleich der Prozessierungsdauer.
Voraussetzungen
Nr. 1 Konto
Sie benötigen ein EO-Lab Konto mit Zugriff auf die Horizon-Schnittstelle: https://cloud.fra1-1.cloudferro.com/auth/login/?next=/.
Nr. 2 Erstellen einer neuen Linux-VM mit virtueller NVIDIA-GPU
So erstellen Sie eine Linux-VM mit virtueller NVIDIA-GPU: Wie erstellt man eine neue Linux-VM mit NVIDIA Virtual GPU im OpenStack Dashboard (Horizon)?.
Nr. 3 Fügen Sie Ihrer VM eine floating IP Addresse hinzu
Wie kann man Floating IPs zu einer VM hinzufügen/entfernen?.
Jetzt können Sie diese floating IP-Adresse für die Beispiele in diesem Artikel verwenden.
Nr. 4 TensorFlow auf Docker installieren
Sie müssen TensorFlow mit Docker auf einer EO-Lab FRA1-1 GPU-fähige virtuelle Maschine installiert haben. Der folgende Artikel beschreibt dies: TensorFlow mit Docker auf einer virtuellen Maschine mit vGPU auf EO-Lab FRA1-1 installieren.
Nr. 5 Lokal auf einem Ubuntu 20.04 LTS Computer ausführen
Dieser Artikel geht davon aus, dass auf Ihrem lokalen Computer Ubuntu 20.04 LTS läuft. Sie können dieses Modell jedoch auch von jedem anderen Betriebssystem aus ausführen, vorausgesetzt, Sie verwenden die entsprechenden Befehle für Dateioperationen, SSH-Zugriff und so weiter.
Code Erläuterung
Dieser Abschnitt enthält eine ausführliche Erläuterung des Verfahrens und des dafür verwendeten Python-Codes. Für die praktischen Schritte, mit denen Sie diesen Arbeitsablauf nachvollziehen können, beginnen Sie bitte mit dem Abschnitt Praktischer Arbeitsablauf (siehe unten). Sie müssen den Python-Code nicht selbst kopieren, eine entsprechende Datei steht für Sie zum Download bereit.
Schritt 1: Datenvorbereitung
Die Datenvorbereitung ist der grundlegende (und in der Regel zeitaufwändigste) Schritt in jedem Data Science-Projekt. Damit unser DL-Modell in der Lage ist zu lernen, werden wir die typische (überwachte) Lernsequenz befolgen:
Organisieren Sie eine ausreichend große Datenmenge (hier: eine Sentinel-2-Beispielszene).
Manuelle Kennzeichnung dieser Daten (durch einen Menschen). In unserem Beispiel haben wir die Bilder manuell in die Kategorien „edges“ und „noedges“ eingeteilt, die jeweils für beschnittene und nicht beschnittene Bilder stehen.
Ein Teil dieser Daten wird als Train(+Validation)-Teilmenge beiseite gelegt, die zum „Anlernen“ des Modells verwendet wird.
Eine andere Teilmenge wird als Test beiseite gelegt. Dabei handelt es sich um eine Kontrollgruppe, die das Modell während der Lernphase nie zu Gesicht bekommt und die zur Bewertung der Modellqualität verwendet wird.
Die herunterladbare .zip Datei, die Sie weiter unten in diesem Artikel finden, ist ein bereits vorbereiteter Datensatz (gemäß diesen Schritten). Sie enthält
592 Dateien des Train/Validate-Sets (50/50 beschnittene/nicht beschnittene Bilder)
148 Dateien des Testsatzes (ebenfalls 50/50 beschnitten/nicht beschnitten).
Basierend auf den Namen der Ordner und Unterordner dieses Datensatzes wird Keras automatisch die Beschriftungen vornehmen, daher ist es wichtig, die Ordnerstruktur beizubehalten.
Der letzte Schritt besteht darin, die notwendigen Operationen an den Daten durchzuführen, damit sie eine geeignete Eingabe für das Modell darstellen. TensorFlow wird einen großen Teil dieser Arbeit für uns erledigen. Zum Beispiel wird mit der Funktion image_dataset_from_directory jedes Bild automatisch beschriftet und in einen Vektor/Matrix von Zahlen umgewandelt: Höhe x Breite x Tiefe (RGB-Ebene).
Für Ihren speziellen Anwendungsfall müssen Sie möglicherweise verschiedene Optimierungen der Daten in diesem Schritt vornehmen.
import numpy as np
import tensorflow as tf
from tensorflow import keras
import pandas as pd
# DATEN BEREITSTELLUNG
# -------------------------------------------------------------------------------------
# Bereitstellen der Trainings-, Validierungs- und Testdatensätze aus Bildordnern.
# Die Labels (edges vs. noedges) werden automatisch aus den Ordnernamen abgeleitet.
train_ds = keras.utils.image_dataset_from_directory(
directory='./data/train',
labels='inferred',
label_mode='categorical',
validation_split=0.2,
subset='training',
image_size=(343, 343),
seed=123,
batch_size=8)
val_ds = keras.utils.image_dataset_from_directory(
directory='./data/train',
labels='inferred',
label_mode='categorical',
validation_split=0.2,
subset='validation',
image_size=(343, 343),
seed=123,
batch_size=8)
test_ds = keras.utils.image_dataset_from_directory(
directory='./data/test',
labels='inferred',
label_mode='categorical',
image_size=(343, 343),
shuffle = False,
batch_size=1)
Schritt 2: Definieren und Trainieren des Modells
Die Definition eines optimalen Modells ist eine zentrale Herausforderung in der Datenwissenschaft. Was wir hier zeigen, ist lediglich ein einfaches Beispielmodell. Sie sollten in anderen Quellen mehr über die Erstellung von Modellen für reale Szenarien lesen.
Sobald das Modell definiert ist, wird es kompiliert und sein Training beginnt. Jede Epoche ist die nächste Iteration bei der Abstimmung des Modells. Diese Epochen sind komplexe und rechenintensive Operationen. Die Verwendung von vGPU ist für Deep-Learning-Anwendungen von grundlegender Bedeutung, da sie die Verteilung von Mikroaufgaben auf Hunderte von Kernen ermöglicht und so den Prozess immens beschleunigt.
Sobald das Modell angepasst ist, werden wir es speichern und für die Erstellung von Vorhersagen wiederverwenden.
# TRAINING
# -------------------------------------------------------------------------------------
# Build, compile and fit the Deep Learning model
model = keras.applications.Xception(
weights=None, input_shape=(343, 343, 3), classes=2)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics='accuracy')
model.fit(train_ds, epochs=5, validation_data=val_ds)
model.save('model_save.h5')
# to reuse the model later:
#model = keras.models.load_model('model_save.h5')
Schritt 3: Generierung von Vorhersagen für die Testdaten
Sobald das Modell trainiert wurde, ist die Erstellung der Vorhersagen ein einfacher und viel schnellerer Vorgang. Wie zuvor beschrieben, werden wir das Modell verwenden, um Vorhersagen für die Testdaten zu erstellen.
# GENERATE PREDICTIONS on previously unseen data
# -------------------------------------------------------------------------------------
predictions_raw = model.predict(test_ds)
Schritt 4: Zusammenfassung der Resultate
In diesem Schritt nehmen wir die tatsächlichen Beschriftungen („edges“ vs. „noedges“, die „beschnittene“ vs. „nicht beschnittene“ Bilder darstellen) und vergleichen sie mit den Beschriftungen, die unser Modell vorhergesagt hat.
Wir fassen die Ergebnisse in einem Datensatz zusammen, der als CSV-Datei gespeichert wird und die Interpretation der tatsächlichen Ergebnisse in der Testmenge im Vergleich zu den vom Modell gelieferten Vorhersagen ermöglicht.
Beispiel für die CSV-Ausgabe:
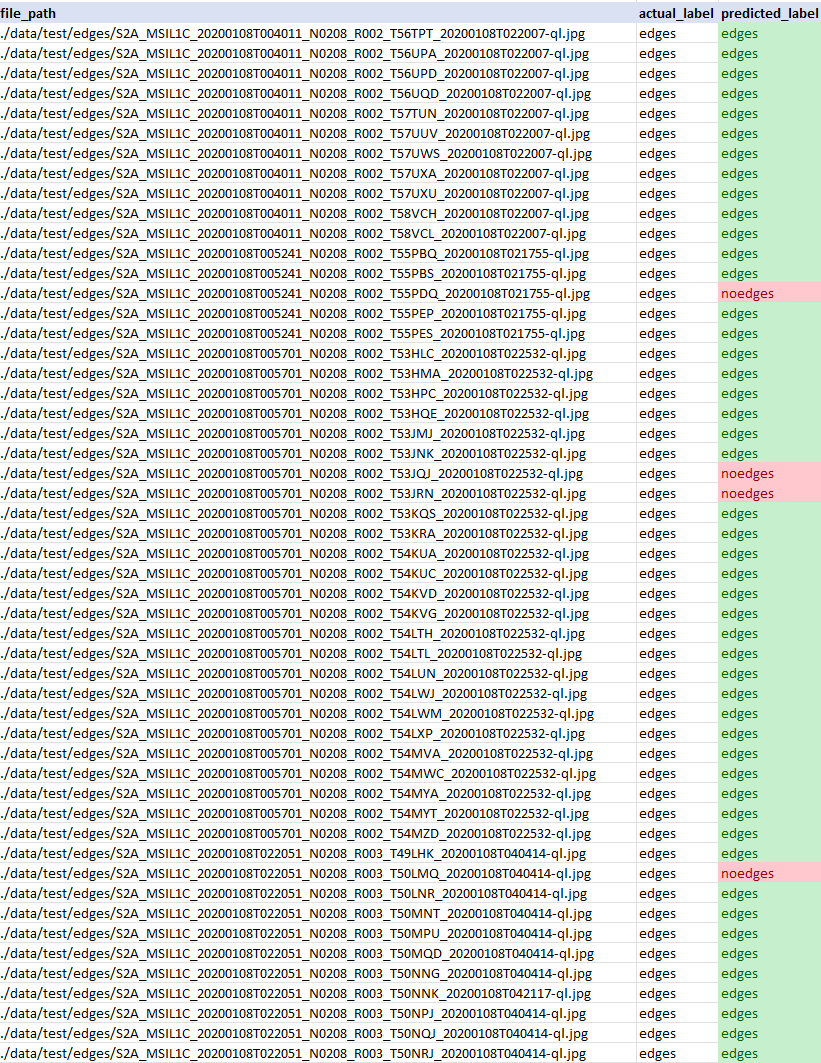
# SUMMARIZE RESULTS (convenience, alternative approaches are available)
# -------------------------------------------------------------------------------------
# initialize pandas dataframe with file paths
df = pd.DataFrame(data = {"file_path": test_ds.file_paths})
class_names = test_ds.class_names # ["edges","noedges"]
# add actual labels column
def get_actual_label(label_vector):
for index, value in enumerate(label_vector):
if (value == 1):
return class_names[index]
actual_label_vectors = np.concatenate([label for data, label in test_ds], axis=0).tolist() # returns array of label vectors [[0,1],[1,0],...] representing category (edges/noedges)
actual_labels = list(map(lambda alv: get_actual_label(alv), actual_label_vectors))
df["actual_label"] = actual_labels
# add predicted labels column
predictions_binary = np.argmax(predictions_raw, axis=1) # flatten to 0-1 recommendation
predictions_labeled = list(map(lambda x: class_names[0] if x == 0 else class_names[1],list(predictions_binary)))
df["predicted_label"] = predictions_labeled
df.to_csv("results.csv", index=False)
Praktischer Arbeitsablauf
Dieser Abschnitt enthält praktische Schritte, mit denen Sie diesen Arbeitsablauf selbst durchführen können. Dies ist nur ein Beispiel und Sie können selbst einen anderen Arbeitsablauf erstellen.
Bitte lesen Sie den Abschnitt Voraussetzungen noch einmal durch, bevor Sie die folgenden praktischen Schritte durchführen.
Sie können die erforderlichen Dateien mit verschiedenen Methoden auf Ihre virtuelle Maschine übertragen, wie z. B.:
- Laden Sie die Dateien auf Ihren lokalen Computer herunter und kopieren Sie sie mit scp auf Ihre virtuelle Maschine
Klicken Sie auf die folgenden Links, um die Daten herunterzuladen
- Laden Sie die Dateien mit wget direkt auf Ihre virtuelle Maschine herunter.
Diese Methode wird in Schritt 1 beschrieben.
Schritt 1: Laden Sie die Ressourcen auf Ihre virtuelle Maschine herunter
Verbinden Sie sich mit Ihrer virtuellen Maschine über SSH (ersetzen Sie 64.225.129.70 durch die floating IP-Adresse Ihrer virtuellen Maschine).
ssh eouser@64.225.129.70
Bemerkung
Überspringen Sie den Rest dieses Schrittes, wenn Sie die Dateien bereits mit einer anderen Methode auf Ihre virtuelle Maschine übertragen haben.
Laden Sie die erforderlichen Ressourcen mit dem folgenden Befehl auf Ihre virtuelle Maschine herunter:
wget https://creodias.docs.cloudferro.com/en/latest/_downloads/3ec8990b08af7d4478a6820abb172705/data.zip https://creodias.docs.cloudferro.com/en/latest/_downloads/1c3a17567b2f4f1ff87ddbbfe005db42/deeplearning.py
Führen Sie den Befehl ls aus, um zu überprüfen, ob die Dateien, die Sie kopiert haben, vorhanden sind:

Schritt 2: Verschieben Sie die heruntergeladenen Ressourcen an den entsprechenden Ort
Erstellen Sie auf Ihrer VM einen Ordner mit dem Namen deeplearning, in dem Sie die heruntergeladenen Ressourcen ablegen werden:
mkdir deeplearning
Verwenden Sie den folgenden Befehl, um die erforderlichen Dateien in dieses Verzeichnis zu verschieben:
mv deeplearning.py data.zip deeplearning
Gehen Sie zu dem Ordner, den Sie gerade erstellt haben:
cd deeplearning
Schritt 3: Erstellen einer Dockerdatei und der Datei requirements.txt
Installieren Sie den Texteditor nano, falls Sie dies noch nicht getan haben, und erstellen Sie damit eine Dockerdatei in Ihrem aktuellen Arbeitsverzeichnis (eine Textdatei namens Dockerfile):
sudo apt install nano
nano Dockerfile
Fügen Sie den folgenden Code ein:
# syntax=docker/dockerfile:1
FROM tensorflow/tensorflow:2.11.0-gpu
WORKDIR /app
RUN mkdir data
COPY deeplearning.py .
COPY data ./data
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
Nach dem Einfügen sollte Ihr Bildschirm wie folgt aussehen:
Speichern Sie die Datei und beenden Sie nano mit CTRL+X und Y und dann Enter.
Fügen Sie die Textdatei requirements.txt mit der gleichen Methode in denselben Ordner ein:
nano requirements.txt
Geben Sie den folgenden Inhalt in den Editor ein:
numpy==1.22.4
pandas==1.4.2
Die Verwendung der Datei requirements.txt ist eine Standardmethode in Python, um die benötigten Erweiterungen einzurichten und zu installieren.
Speichern Sie die Datei und beenden Sie nano: CTRL+X, Y, Enter.
Schritt 4: Entpacken und löschen Sie das Archiv mit den Trainingsdaten
Entpacken Sie das Archiv data.zip und löschen Sie es dann:
unzip data.zip
rm data.zip
Schritt 5: Überprüfen Sie, ob sich alle benötigten Dateien am richtigen Ort befinden
Führen Sie den Befehl ls aus, um zu überprüfen, ob die folgenden Dateien vorhanden sind:
Verzeichnis data
Datei deeplearning.py.
Datei Dockerfile
Datei requirements.txt

Schritt 6: Erstellen und Starten Sie ein Docker-Image
Führen Sie in dem Ordner mit der Dockerdatei den folgenden Befehl aus, um das Container-Image zu erstellen:
sudo docker build -t deeplearning .
Tdann starten Sie den Container mit der interaktiven Shell:
sudo docker run -it --gpus all -v /tmp/:/tmp/ deeplearning /bin/bash
Sie sollten die folgende Ausgabe sehen:
Mit der Option -v wird ein Volume gemountet, das von Ihrem Container und Ihrer Host-VM gemeinsam genutzt wird. Dies ermöglicht das Kopieren der von unserem Skript erzeugten Dateien auf die Host-VM.
Schritt 7: Ausführen des Python-Codes
Führen Sie das Python-Skript innerhalb des Containers aus:
python3 deeplearning.py
Auf einer vGPU-fähigen VM sollte die Ausführung dieses Skripts ein paar Minuten dauern. Bei diesem Vorgang sollte eine Datei results.csv erstellt werden, die die Ergebnisse enthält. Um das Training nicht wiederholen zu müssen, wird das Modell außerdem in einer Datei mit dem Namen model_save.h5 gespeichert.
Schritt 8: Extrahieren der Dateien aus dem Container
Im letzten Schritt werden die Dateien aus dem Ordner /tmp im Container in den Ordner /tmp auf dem Host-Rechner kopiert. Führen Sie den folgenden Befehl in der interaktiven Container-Shell aus:
cp results.csv model_save.h5 /tmp
Sie können den Container nun mit folgendem Befehl verlassen:
exit
Nachdem Sie den Container verlassen haben, wechseln Sie in den Ordner /tmp auf Ihrer virtuellen Maschine:
cd /tmp
Verwenden Sie den Befehl ls, um zu überprüfen, ob die Dateien results.csv und model_save.h5, die die Ergebnisse dieser Operation enthalten, dort zu finden sind. Wir werden sie im nächsten Schritt auf Ihren lokalen Computer kopieren.
Sie können nun auch die Verbindung zur virtuellen Maschine trennen:
exit
Schritt 9: Laden Sie die Dateien mit den Ergebnissen auf Ihren lokalen Rechner herunter
Sie werden nun die Ergebnisse und das gespeicherte Modell auf Ihren lokalen Rechner herunterladen. Machen Sie den Ordner, der die Datei results.csv enthält, zu Ihrem aktuellen Arbeitsverzeichnis und führen Sie dann den folgenden Befehl aus (ersetzen Sie 64.225.129.70 durch die floating IP-Adresse Ihres virtuellen Rechners):
scp eouser@64.225.129.70:/tmp/results.csv eouser@64.225.129.70:/tmp/model_save.h5 .
Die csv-Datei mit den Ergebnissen und die Datei mit dem Modell sollten sich jetzt auf Ihrem lokalen Rechner befinden:

Leistungsvergleich
Dieser Artikel hat TensorFlow in einer Docker-Umgebung installiert. Es gibt einen parallelen Artikel mit dem gleichen Beispiel, das direkt auf WAW3-a cloud läuft (Beispiel für einen Deep Learning-Workflow mit einer FRA1-1 vGPU VM EO-Lab). Wir werden nun die Laufzeiten dieser Umgebungen vergleichen, indem wir die kleinste und die größte Variante für vGPUs, vm.a6000.1 und vm.a6000.8, verwenden.
Die folgende Tabelle enthält die Zeit, die für die Ausführung des Python-Codes benötigt wird. Sie wurde mit dem Befehl time („real value“) gemessen. Alle Tests wurden auf EO-Lab FRA1-1 ausgeführt.
vm.a6000.1 |
vm.a6000.8 |
|
mit Docker |
5m50.449s |
1m14.446s |
ohne Docker |
5m0.276s |
0m55.547s |
Der gesamte Prozess war auf der vm.a6000.8-Variante etwa fünfmal schneller als auf der vm.a6000.1-Variante. Es gibt einen kleinen Nachteil bei der Verwendung von Docker, aber das ist zu erwarten.
Bemerkung
Bei diesem Benchmark werden alle Phasen der Ausführung des Python-Codes gezählt und nicht alle profitieren in gleichem Maße von besserer Hardware.
Was als nächstes getan werden kann
Sie können diesen Arbeitsablauf auch ohne die Verwendung von Docker durchführen. Wenn Sie dies tun möchten, lesen Sie bitte den folgenden Artikel: Beispiel für einen Deep Learning-Workflow mit einer FRA1-1 vGPU VM EO-Lab.
Warnung
Die Beispiele in diesem Artikel sind möglicherweise nicht repräsentativ, und Ihre Erfahrungen können variieren. Verwenden Sie diesen Code und den gesamten Artikel als Ausgangspunkt für Ihre eigenen Untersuchungen.